ADR-003: Arquitetura de Precificação Automatizada de Instâncias Reservadas AWS
Status: Proposto
Data: 10/12/2025
Contexto: Módulo de Otimização de Custos - Cálculo de Taxas Horárias de Recursos AWS
Decisores: Equipe FinOps
1. Contexto e Problema
Atualmente, não existe um processo automatizado para calcular a taxa horária efetiva de instâncias reservadas e recursos de infraestrutura AWS (RDS, ElastiCache, OpenSearch). O time de FinOps recebe arquivos CSV contendo listas mistas desses recursos com suas configurações (região, tipo de instância, engine, modelo de pagamento), mas o cálculo manual de precificação é:
- Demorado: Consultas manuais à AWS Price List API são repetitivas e propensas a erros
- Não Escalável: Volume de dados variável dificulta processar grandes lotes
- Inflexível: Novos tipos de serviços AWS exigem retrabalho significativo
- Sem Rastreabilidade: Falta de histórico e auditoria dos cálculos realizados
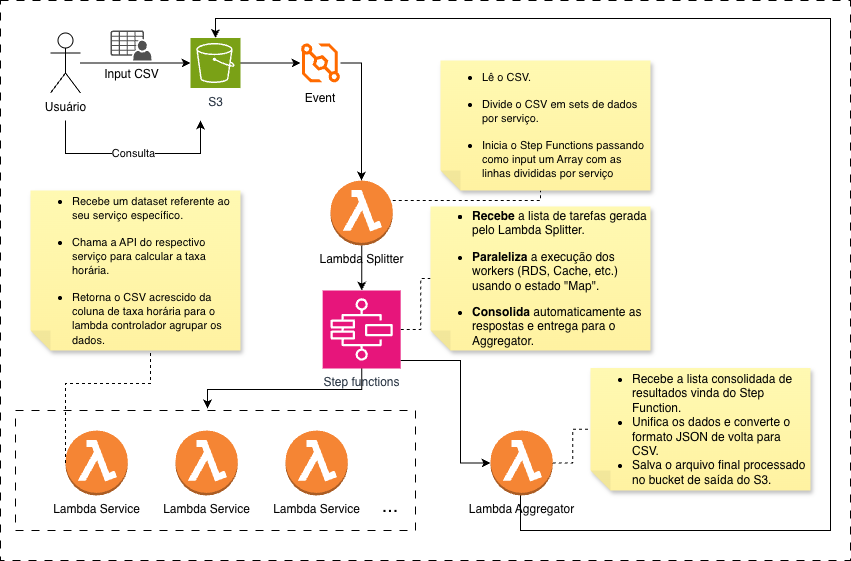
Objetivo: Definir e documentar uma arquitetura serverless event-driven que automatize a precificação de recursos AWS, permitindo processamento paralelo, extensibilidade para novos serviços e alta observabilidade.
2. Decisão Arquitetural
2.1 Arquitetura Escolhida
Implementaremos uma arquitetura Serverless Event-Driven utilizando o padrão Fan-Out (Map-Reduce) orquestrada pelo AWS Step Functions, com Workers especializados em Lambda para cada tipo de serviço AWS.
Princípios de Design:
- Segregação de Responsabilidades: Cada Worker Lambda contém lógica hardcoded e otimizada para um único serviço
- Processamento Paralelo: Utilização de Step Functions Map State para paralelizar cálculos
- Stateless: Sem necessidade de banco de dados (DynamoDB) para configurações
- Event-Driven: Gatilho automático via S3 Event Notification
- Observabilidade: CloudWatch centralizado com alertas para serviços não mapeados
Fluxo de dados:
Amazon S3 (Input Bucket)
↓ [S3 Event]
AWS Step Functions (State Machine)
↓
Lambda Router/Splitter
↓
Step Functions Map State (Parallel Processing)
├─→ Lambda Worker RDS
├─→ Lambda Worker ElastiCache
├─→ Lambda Worker OpenSearch
└─→ [Future Workers...]
↓
Lambda Aggregator
↓
Amazon S3 (Output Bucket) + CloudWatch Logs
3. Componentes da Arquitetura
3.1 Fluxo de Trabalho (Workflow)
Etapa 1: Gatilho de Processamento
Serviço: Amazon S3 + S3 Event Notification
Descrição: Upload de arquivo CSV no bucket de entrada (s3://finops-pricing-input/) dispara automaticamente a execução da Step Functions State Machine.
Configuração:
- Event Type:
s3:ObjectCreated:* - Filter: Suffix
.csv - Target: Step Functions State Machine ARN
Etapa 2: Router/Splitter Lambda
Função: pricing-router-function
Runtime: Python 3.11
Responsabilidades:
- Ler CSV bruto do S3 (parsing com biblioteca
csvnativa do Python) - Validar estrutura do arquivo (colunas obrigatórias:
service_type,region,instance_type,engine,payment_model) - Segregar linhas em datasets JSON por tipo de serviço:
{ "rds": [...], "elasticache": [...], "opensearch": [...], "unmapped": [...] } - Passar datasets para próximo estado da Step Functions
Exemplo de Implementação (CSV Nativo):
import csv
import boto3
from io import StringIO
s3_client = boto3.client('s3')
def lambda_handler(event, context):
# Obter CSV do S3
bucket = event['bucket']
key = event['key']
csv_obj = s3_client.get_object(Bucket=bucket, Key=key)
csv_content = csv_obj['Body'].read().decode('utf-8')
# Parse CSV usando biblioteca nativa
csv_reader = csv.DictReader(StringIO(csv_content))
# Validar colunas obrigatórias
required_columns = {'service_type', 'region', 'instance_type', 'engine', 'payment_model'}
if not required_columns.issubset(csv_reader.fieldnames):
raise ValueError(f"Missing required columns: {required_columns - set(csv_reader.fieldnames)}")
# Segregar por tipo de serviço
datasets = {
'rds': [],
'elasticache': [],
'opensearch': [],
'unmapped': []
}
for row in csv_reader:
service_type = row.get('service_type', '').lower()
if service_type in datasets:
datasets[service_type].append(row)
else:
datasets['unmapped'].append({
**row,
'error': f"Service type '{service_type}' not recognized"
})
# Retornar datasets para Step Functions
return {
'datasets': [
{'serviceType': service_type, 'items': items}
for service_type, items in datasets.items()
if items # Apenas datasets com dados
]
}
Tratamento de Exceções:
- Serviços desconhecidos/novos → Agrupados em dataset
unmappede logados no CloudWatch - Linhas inválidas → Logadas em CloudWatch com contexto (linha, erro)
- CSV vazio/corrompido → Falha controlada com log
Etapa 3: Orquestração com Step Functions
State Machine: PricingCalculatorStateMachine
Tipo: Standard Workflow
Definição (Amazon States Language):
{
"Comment": "Pricing Calculator Workflow - Fan-Out Pattern",
"StartAt": "RouterSplitter",
"States": {
"RouterSplitter": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:pricing-router-function",
"Next": "ProcessDatasets",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "LogFailure"
}
]
},
"ProcessDatasets": {
"Type": "Map",
"ItemsPath": "$.datasets",
"MaxConcurrency": 10,
"Iterator": {
"StartAt": "RouteByServiceType",
"States": {
"RouteByServiceType": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.serviceType",
"StringEquals": "rds",
"Next": "InvokeWorkerRDS"
},
{
"Variable": "$.serviceType",
"StringEquals": "elasticache",
"Next": "InvokeWorkerElastiCache"
},
{
"Variable": "$.serviceType",
"StringEquals": "opensearch",
"Next": "InvokeWorkerOpenSearch"
}
],
"Default": "LogUnmapped"
},
"InvokeWorkerRDS": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:pricing-worker-rds",
"End": true
},
"InvokeWorkerElastiCache": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:pricing-worker-elasticache",
"End": true
},
"InvokeWorkerOpenSearch": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:pricing-worker-opensearch",
"End": true
},
"LogUnmapped": {
"Type": "Pass",
"Result": "Unmapped service type - logged to CloudWatch",
"End": true
}
}
},
"Next": "AggregateResults"
},
"AggregateResults": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:pricing-aggregator-function",
"Next": "Success"
},
"Success": {
"Type": "Succeed"
},
"LogFailure": {
"Type": "Pass",
"Result": "Workflow failed - check CloudWatch Logs",
"End": true
}
}
}
Etapa 4: Workers Especialistas (Lambdas)
Cada Worker contém lógica otimizada e hardcoded para consultar a AWS Price List API com filtros específicos do serviço.
Worker RDS
Função: pricing-worker-rds
Runtime: Python 3.11
Lógica de Pricing:
import boto3
import json
pricing_client = boto3.client('pricing', region_name='us-east-1')
def calculate_rds_pricing(resource):
"""
resource = {
"region": "us-east-1",
"instance_type": "db.t3.medium",
"engine": "mysql",
"payment_model": "Reserved",
"deployment_option": "Multi-AZ",
"term_length": "1yr"
}
"""
filters = [
{"Type": "TERM_MATCH", "Field": "instanceType", "Value": resource["instance_type"]},
{"Type": "TERM_MATCH", "Field": "databaseEngine", "Value": resource["engine"]},
{"Type": "TERM_MATCH", "Field": "deploymentOption", "Value": resource["deployment_option"]},
{"Type": "TERM_MATCH", "Field": "location", "Value": get_location_from_region(resource["region"])},
]
response = pricing_client.get_products(
ServiceCode='AmazonRDS',
Filters=filters,
MaxResults=100
)
# Processar response e extrair preço efetivo por hora
hourly_rate = extract_reserved_hourly_rate(response, resource["term_length"])
return {
**resource,
"hourly_rate_usd": hourly_rate,
"currency": "USD"
}
Permissões IAM Necessárias:
- Effect: Allow
Action:
- pricing:GetProducts
Resource: "*"
Condition:
StringEquals:
aws:RequestedRegion:
- us-east-1
- ap-south-1
Worker ElastiCache
Função: pricing-worker-elasticache
Runtime: Python 3.11
Filtros Específicos:
cacheEngine: redis, memcachedusageType: Cache usage type (ex:USE2-NodeUsage:cache.t3.medium)locationType: AWS Region
Worker OpenSearch
Função: pricing-worker-opensearch
Runtime: Python 3.11
Filtros Específicos:
instanceType: OpenSearch instance type (ex:t3.medium.search)productFamily: OpenSearch ServicestorageType: EBS-backed, Instance Store
Etapa 5: Agregação (Lambda Aggregator)
Função: pricing-aggregator-function
Runtime: Python 3.11
Responsabilidades:
- Consolidar resultados dos Workers (merge de arrays JSON)
- Gerar CSV final com colunas adicionais:
hourly_rate_usd,currency,calculated_at - Upload para S3 Output Bucket (
s3://finops-pricing-output/) - Publicar métricas no CloudWatch:
- Total de recursos processados
- Recursos não mapeados (unmapped)
- Tempo total de processamento
- Taxa de erro por Worker
Formato do CSV de Saída:
service_type,region,instance_type,engine,payment_model,deployment_option,term_length,hourly_rate_usd,currency,calculated_at
rds,us-east-1,db.t3.medium,mysql,Reserved,Multi-AZ,1yr,0.068,USD,2025-12-10T14:32:00Z
elasticache,us-west-2,cache.t3.small,redis,OnDemand,Single-AZ,,0.034,USD,2025-12-10T14:32:05Z
3.2 Serviços AWS Utilizados
| Serviço | Função |
|---|---|
| Amazon S3 | Armazenamento de entrada (Input) e saída (Output) |
| AWS Lambda | Execução de código (Router, Workers, Aggregator) |
| AWS Step Functions | Orquestração de estado e paralelismo (State Machine) |
| AWS Price List Service API | Fonte dos dados de precificação (regiões específicas) |
| Amazon CloudWatch | Logs, Métricas e Alarmes |
3.3 Considerações Técnicas: Dependências Lambda
Estratégia de Dependências Mínimas
Para otimizar cold start e reduzir o tamanho do pacote Lambda, adotamos a estratégia de usar apenas bibliotecas nativas do Python sempre que possível.
Dependências por Lambda:
| Lambda Function | Dependências | Tamanho Total |
|---|---|---|
pricing-router-function |
csv (built-in), boto3 (runtime) |
~5 MB |
pricing-worker-* |
boto3 (runtime), json (built-in) |
~5 MB |
pricing-aggregator |
csv (built-in), boto3 (runtime) |
~5 MB |
Justificativa da Escolha:
- Zero Overhead: Biblioteca
csvé nativa do Python (não adiciona bytes ao pacote) - Cold Start Otimizado: Sem dependências externas = inicialização em <500ms
- Memória Eficiente: Processa CSVs até 10MB com apenas 128MB de RAM Lambda
- Manutenção Simplificada: Menos vulnerabilidades (CVEs) e atualizações de dependências
Exemplo de Implementação do Aggregator:
import csv
import boto3
from io import StringIO
from datetime import datetime
s3_client = boto3.client('s3')
def lambda_handler(event, context):
# Merge de resultados dos Workers
all_results = []
for dataset in event['results']:
all_results.extend(dataset['items'])
# Gerar CSV usando biblioteca nativa
output = StringIO()
if all_results:
fieldnames = list(all_results[0].keys())
writer = csv.DictWriter(output, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(all_results)
# Upload para S3
timestamp = datetime.utcnow().strftime('%Y%m%d_%H%M%S')
output_key = f"pricing_output_{timestamp}.csv"
s3_client.put_object(
Bucket='finops-pricing-output',
Key=output_key,
Body=output.getvalue(),
ContentType='text/csv',
Metadata={
'processed_at': datetime.utcnow().isoformat(),
'total_resources': str(len(all_results))
}
)
return {
'statusCode': 200,
'output_file': output_key,
'total_processed': len(all_results)
}
3.4 Permissões e Acessos Necessários (IAM Roles)
IAM Role: PricingRouterLambdaRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: S3InputAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:ListBucket
Resource:
- arn:aws:s3:::finops-pricing-input
- arn:aws:s3:::finops-pricing-input/*
- PolicyName: CloudWatchLogsAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: arn:aws:logs:*:*:*
IAM Role: PricingWorkerLambdaRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: PricingAPIAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- pricing:GetProducts
Resource: "*"
Condition:
StringEquals:
aws:RequestedRegion:
- us-east-1
- ap-south-1
- PolicyName: CloudWatchLogsAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: arn:aws:logs:*:*:*
IAM Role: PricingAggregatorLambdaRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: S3OutputAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- s3:PutObject
- s3:PutObjectAcl
Resource:
- arn:aws:s3:::finops-pricing-output/*
- PolicyName: CloudWatchMetrics
PolicyDocument:
Statement:
- Effect: Allow
Action:
- cloudwatch:PutMetricData
Resource: "*"
- PolicyName: CloudWatchLogsAccess
PolicyDocument:
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: arn:aws:logs:*:*:*
IAM Role: StepFunctionsExecutionRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: states.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: InvokeLambdas
PolicyDocument:
Statement:
- Effect: Allow
Action:
- lambda:InvokeFunction
Resource:
- arn:aws:lambda:*:*:function:pricing-router-function
- arn:aws:lambda:*:*:function:pricing-worker-rds
- arn:aws:lambda:*:*:function:pricing-worker-elasticache
- arn:aws:lambda:*:*:function:pricing-worker-opensearch
- arn:aws:lambda:*:*:function:pricing-aggregator-function
4. Implicações
Operacionais:
- Redução no tempo de precificação manual
- Processamento paralelo de Workers simultâneos (configurável)
- Rastreabilidade com logs no CloudWatch Logs Insights
Técnicos:
- Alta disponibilidade nativa do AWS Lambda (99.95% SLA)
- Retry automático via Step Functions (exponential backoff)
- Escalabilidade automática sem provisionamento de infraestrutura
Financeiros:
- Modelo de custo pay-per-use (sem custo fixo de infraestrutura)
- Otimização de chamadas à Price List API (batch requests por Worker)
- Redução de custos operacionais com automação (FTE savings)
Estratégicos:
- Extensibilidade para novos serviços AWS (ex: Redshift, Neptune) com baixo esforço
- Base para futuros módulos de otimização de custos
- Observabilidade para serviços não mapeados permite roadmap data-driven
5. Diagrama de Arquitetura
6. Referências
- AWS Step Functions
- AWS Price List Service API Documentation
- Calling AWS services and prices using the AWS Price List
7. Observações sobre a Implementação Atual
⚠️ A implementação atual não aborda a arquitetura proposta na ADR por completo. O sistema opera em modelo simplificado com uma única Lambda Function, sem AWS Step Functions ou Workers especializados.
Características da Implementação Atual:
- Arquitetura: Lambda monolítica (
awsPricingApi) com módulos internos - Processamento: Sequencial (não paralelo) por serviço
- Orquestração: Gerenciada internamente pelo
handler.py - Componentes:
csv_splitter.py,pricing_processor.py,RDSPricingService,ElastiCachePricingService,OpenSearchPricingService,aggregator_utils.py
Fluxo Atual:
Amazon S3 (Input Bucket)
↓ [S3 Event Notification]
AWS Lambda: awsPricingApi
├─ Leitura do CSV (s3_reader.py)
├─ Segregação por serviço (csv_splitter.py)
├─ Chamadas sequenciais à AWS Price List API (pricing_processor.py)
├─ Agregação de resultados (aggregator_utils.py)
└─ Escrita do CSV final (s3_writer.py)
↓
Amazon S3 (Output Bucket)
Última Atualização: 11/12/2025
Versão: 1.0
Autores: Gabriel Pepe
Revisores: [A definir]